如何下载期刊的封面和目录页?
如何高清的拷贝pdf中的图片?如何选择合适的影像学检查?(供临床医生了解)2021年(第九版)北大核心期刊目录(医学类)
2021年科技核心(统计源核心)期刊目录
影像组学分析流程及注意事项、临床应用简介(适合入门)
影像组学内容合集磁共振ASL成像原理及临床应用
弥散成像DKI、IVIM介绍医工交叉融合影像创新专题会议回放
如何免费中英文电子书下载,贫民窟学子必备!
影像组学研究设计 刘再毅教授梁长虹教授-人工智能与影像组学洞悉医学影像数据医学影像AI临床应用的现状和挑战-刘再毅影像组学内容合集影像组学常用的一些工具(软件)影像组学入门知识(一)影像医师临床科研选题与推进的挑战和机遇-田捷教授
沈君-从临床病例到影像学的科研选题韩璎-国自然标书写作技巧
张龙江-医学影像学SCI论文写作体会
科研实用工具
RadiAnt DICOM Viewer全能破解版
pdf编辑软件—Adobe Acrobat Pro破解版(校稿必备)
百度网盘不限速下载(供影像同道使用)
小巧便携屏幕录制工具——oCam备你不时之需
别再用SPSS作图啦,GraphPad Prism助你一臂之力(附软件)
作图神器GraphPad Prism的统计功能及模块讲解(附软件)
SciHub Pro 6.2 文献免费批量下载神器!
文献下载神器
知云翻译阅读器@破解版!
小工具助你pdf文件-转一切
PDF Shaper Pro(pdf转换工具)
pdf编辑软件—Adobe Acrobat Pro破解版(校稿必备)
实用软件:B站视频批量下载
电脑文件搜索神器Everything,拯救你的桌面
文献小镇-一个免费下载中英文文献的网站
1、导读
图像分割是计算机视觉三大任务之一,基于深度学习的图像分割技术也发挥日益重要的作用,广泛应用于智慧医疗、工业质检、自动驾驶、遥感、智能办公等行业。

而在智慧医疗领域,3D医疗影像分割是一个比较热门的方向。其通过学习3D医疗影像数据(CT、MRI)和特定标签的映射关系,获取3D的特定感兴趣器官、组织的立体分割结果。 进一步结合3D打印、数据分析、可视化等技术,就可以帮助医生对患者的病情进行高效诊断、手术规划、疾病研究等重要工作。 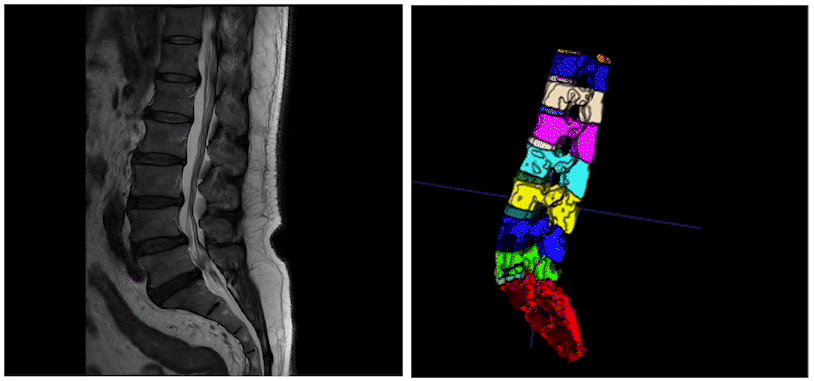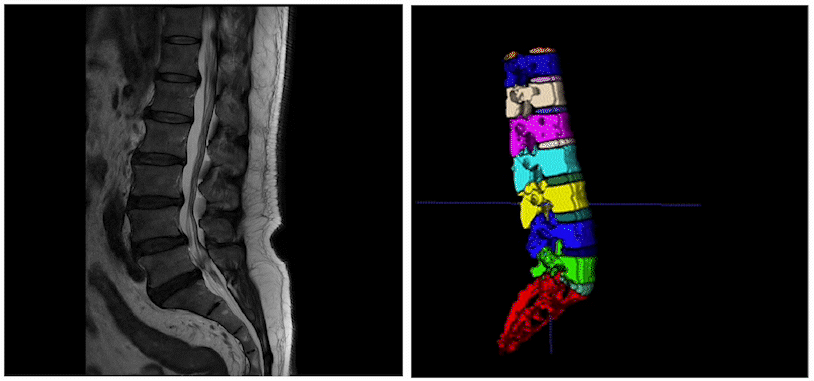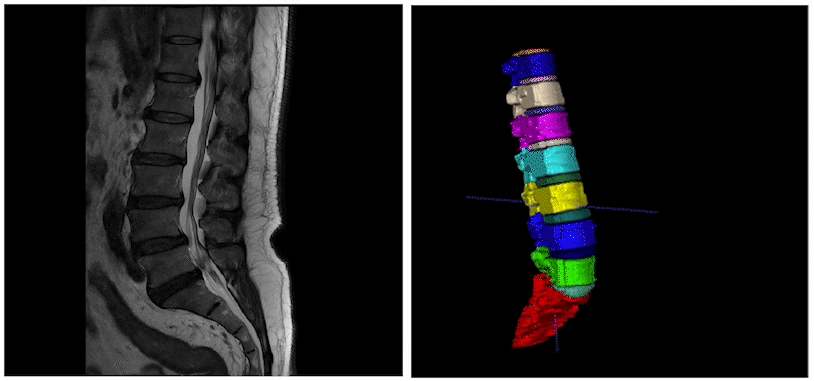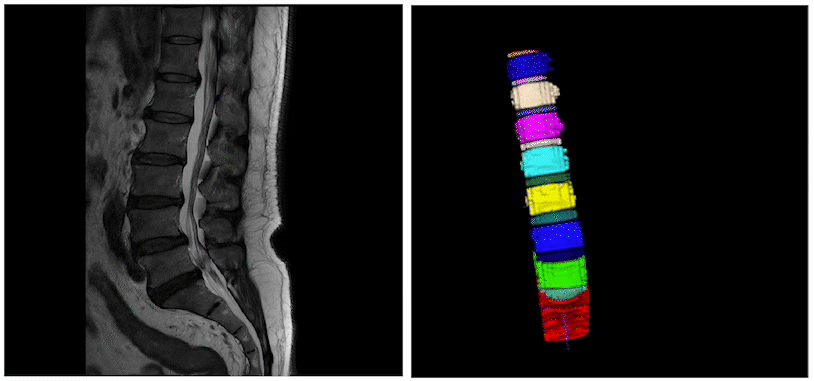 今天这篇文章就和大家分享一下3D医疗影像分割技术的最新进展
今天这篇文章就和大家分享一下3D医疗影像分割技术的最新进展
 https://github.com/PaddlePaddle/PaddleSeg
https://github.com/PaddlePaddle/PaddleSeg  2、MedicalSegV2:高精度定制化3D医疗分割方案
2、MedicalSegV2:高精度定制化3D医疗分割方案
基于百度飞桨开发的MedicalSeg一直致力于帮助大家快速上手并进行3D医疗影像分割的相关应用。MdeicalSegV1 提供了从高精度数据处理、模型训练、可视化验证到部署的全流程,方便医疗从业者快速构建医疗识别模型,高效进行图像识别。在V1推出后的半年间,我们又针对医疗影像分割中的多个难点对MedicalSegV1进行了重磅升级: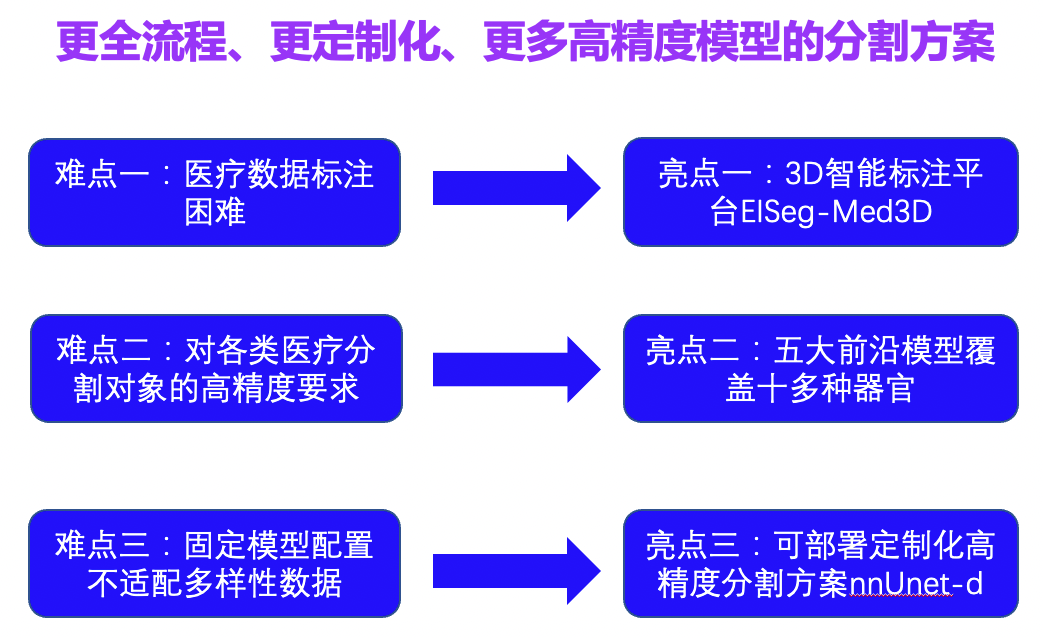 升级之后的飞桨3D医疗影像分割开发套件如下图所示:
升级之后的飞桨3D医疗影像分割开发套件如下图所示: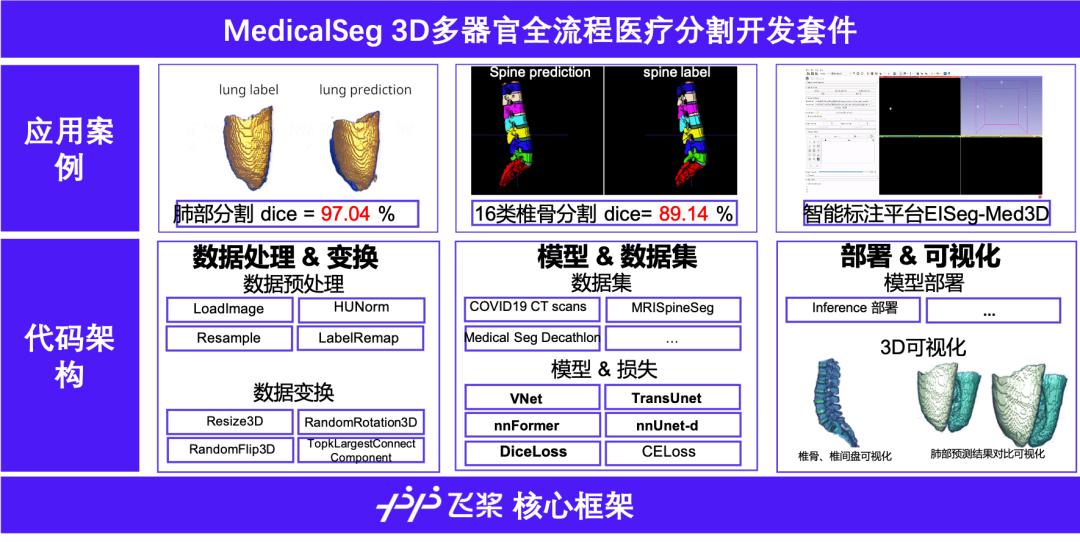 基于自研模型的3D智能标注平台EISeg-Med3D
基于自研模型的3D智能标注平台EISeg-Med3D
医疗影像分割中的一个源头性问题为数据标注极为困难,专业医生需要通过极为繁杂的标注流程、多重质量保证机制来生成大量、准确标注结果。为了缓解这个问题。PaddleSeg团队创新性地将3D网络应用于交互式分割流程中,并实现100 % 3D数据流,形成了基于3D交互式分割的智能标注平台EISeg-Med3D。
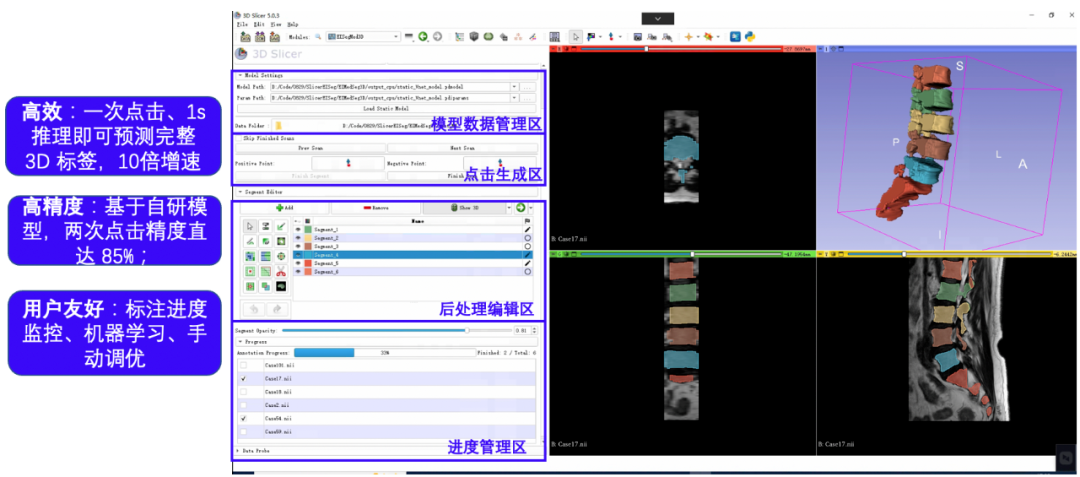
EISeg-Med3D基于3D Slicer搭建,具有高效、高精度、用户友好三大特点:只要一次点击1s生成3D标注结果,相比2D标注实现十倍提速;两次点击就可达到85% 精度,结合搭载的机器学习图像算法、手工微调工具,实现100% 高精度标注;拥有标注进度管理、三步轻松安装、历史标注结果自动导入等用户友好设计。极大丰富的高精度多器官前沿模型
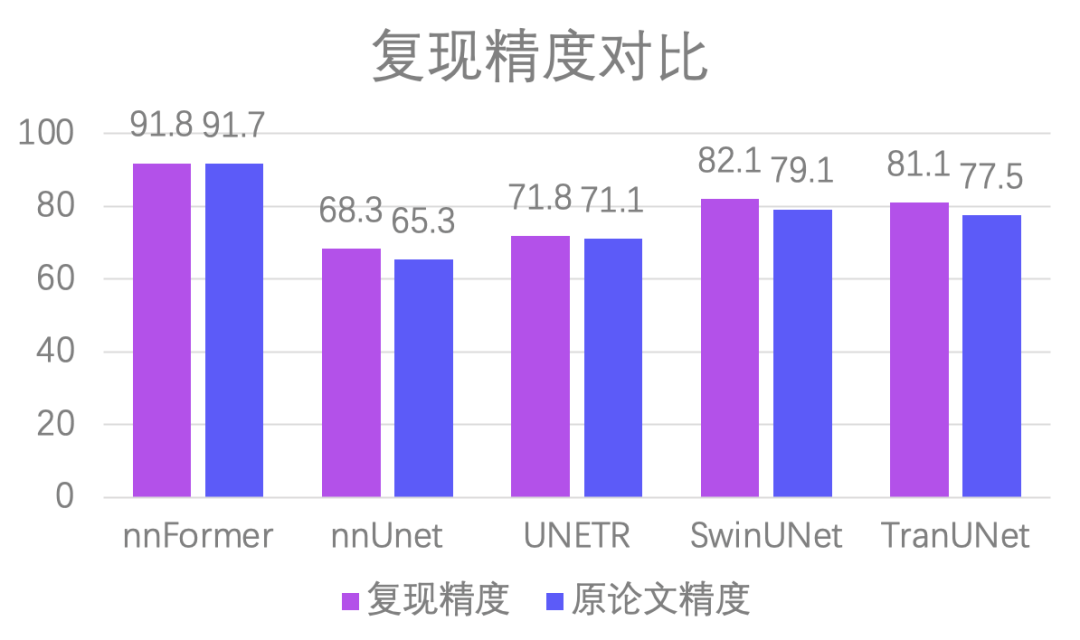
从v1到v2,MedicalSeg的内置分割算法从单个VNet丰富到6个SOTA算法,扩充的模型数量提供了更为先进高效的分割性能,覆盖了18种各类器官组织。如下表,复现的模型对比原算法还有至多3.62的提升。
 定制化医疗分割方案nnUNet
定制化医疗分割方案nnUNet
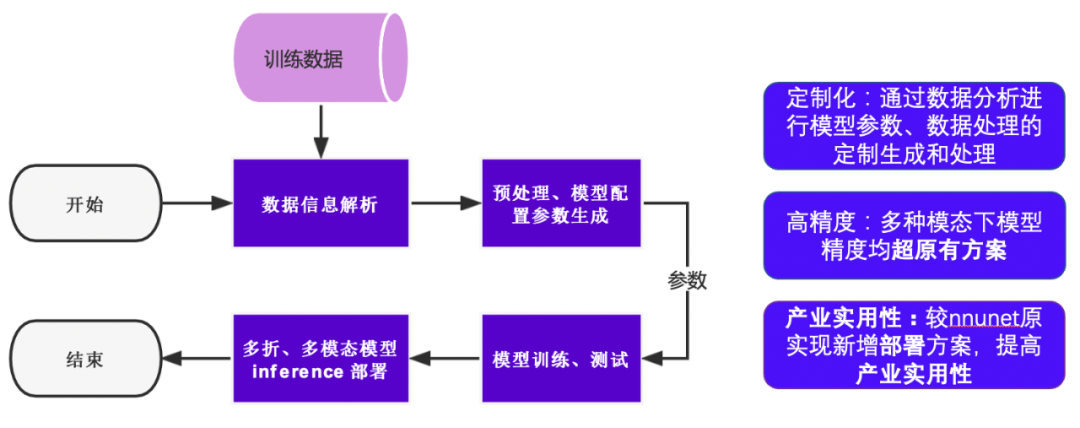
有过医疗分割经验的开发者一定听过nnUNet,作为各大比赛的打榜方案,其支持数据定制化下的高精度分割。而看过其代码的开发者也会发现其代码的晦涩难懂。为了支持大家更加灵活使用nnUNet的需要,我们基于飞桨对其进行了模块化、清晰化的复现;同时还新增了在静态图预测时匹配多种模型、多折模型的部署方案,达到同一张图像可使用多折静态模型部署的效果,从而大大提升了其产业实用性。
MedicalSegV2传送门:https://github.com/PaddlePaddle/PaddleSeg/tree/develop/contrib/MedicalSeg3、PaddleSeg其他升级
除了智慧医疗3D影像分割的难点,图像分割依旧面临诸多挑战,比如:分割数据标注效率较低,标注过程自动化程度低;垂类场景多样,打造全流程方案的难度大等。针对以上挑战,飞桨图像分割开源套件PaddleSeg近期还对如下方向进行了升级:
一、针对标注数据的难题,发布智能标注平台EISeg正式版,支持医疗、遥感、工业质检等领域的分割标注,新增视频分割标注,分割标注效率提升超过10倍。
二、针对人像分割场景,发布实时人像分割SOTA方案PP-HumanSegV2,推理速度提升87.15%,分割精度达到96.63%,可视化效果更佳,可与商业收费方案媲美。
三、开源NeurIPS 2022顶会发表的语义分割模型RTFormer,结合CNN和Transformer的优点,该模型设计并使用了高效的RTFormer Block。对比其他实时语义分割模型,RTFormer在多个数据集上实现SOTA精度和速度(后续会有单独文章详细解读)。4、其他技术升级详细解析
4.1 EISeg正式版,标注效率提升超10倍通用场景的智能标注EISeg基于深度学习模型,能够结合用户提供的标注信息灵活选择用户感兴趣的区域。在EISeg中,用户通过点击正点或负点来选择需要被分割的目标,不需要再对目标周围进行点击和拉线。它能减少用户交互的次数,提升标注效率
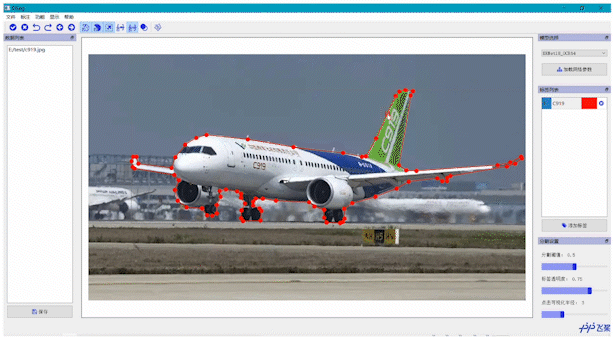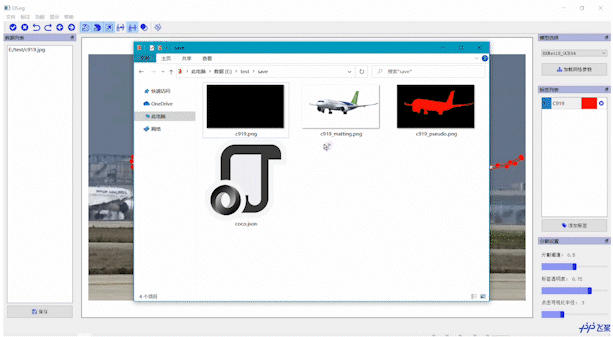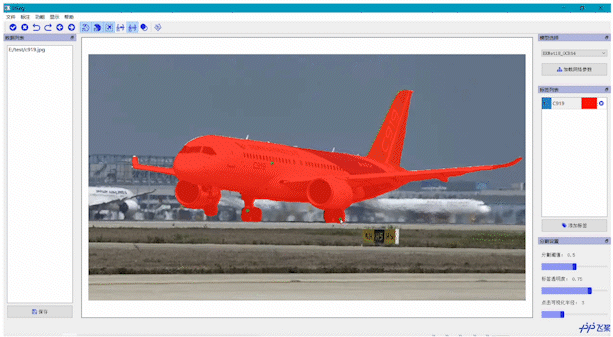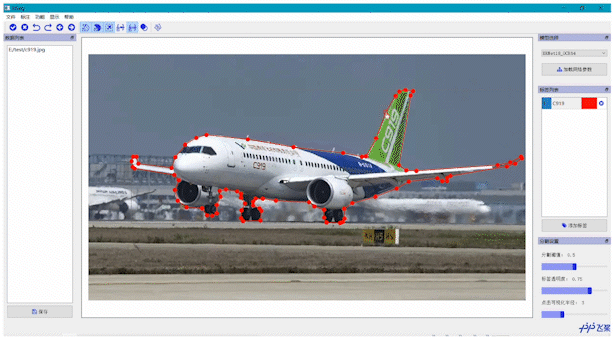
医疗、遥感垂类场景的智能标注EISeg针对特定数据集进行训练并获得了高质量的交互式分割模型,目前覆盖的场景包括: 医疗腹腔多器官、椎骨分割、产品瑕疵分割、遥感建筑物分割等。同时,针对不同场景的标注需求,EISeg提供了相应的特色标注能力,比如遥感图像支持遥感信息的读取,医疗图像支持窗宽窗位的选择等,从而拓展了交互式分割的应用领域。

业界领先的内置分割模型目前EISeg提供的各类模型能够达到业界的领先水平,EISeg通用模型精度和速度如下表所示:
支持视频智能标注EISeg正式版视频标注工具以交互式分割算法及交互式视频分割算法MiVOS为基础,涵盖了通用、腹腔多器官,CT椎骨等不同方向的高质量交互式视频分割模型,方便开发者快速实现视频的分割标注。
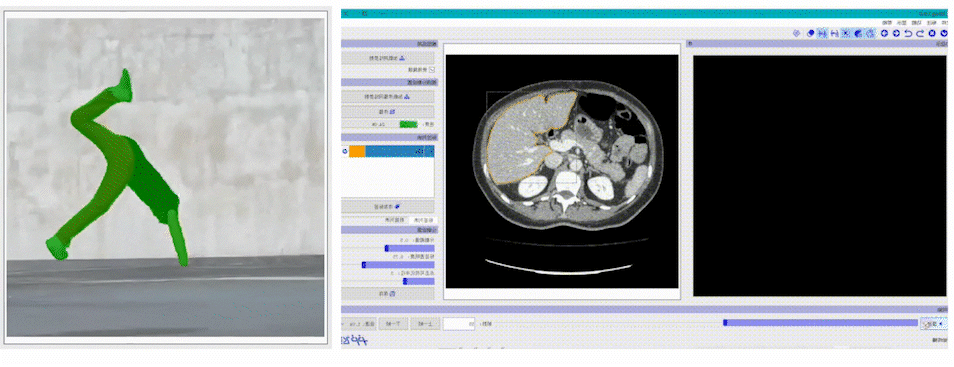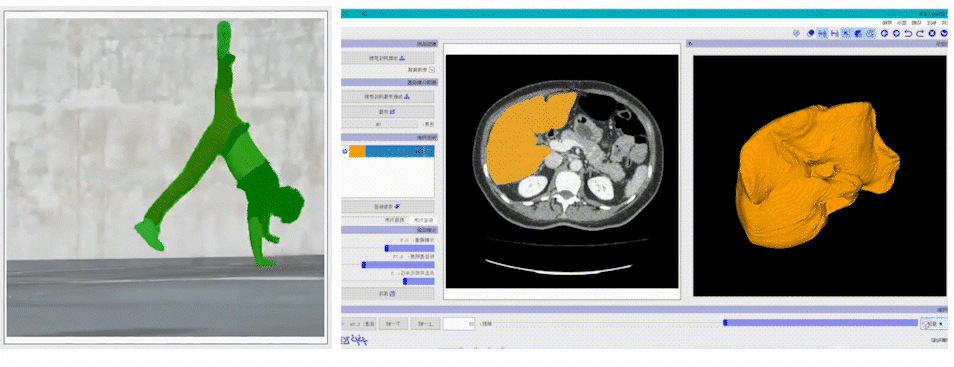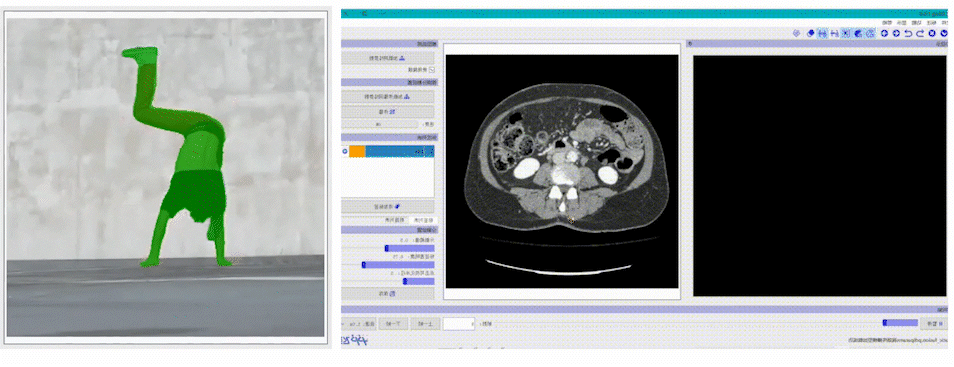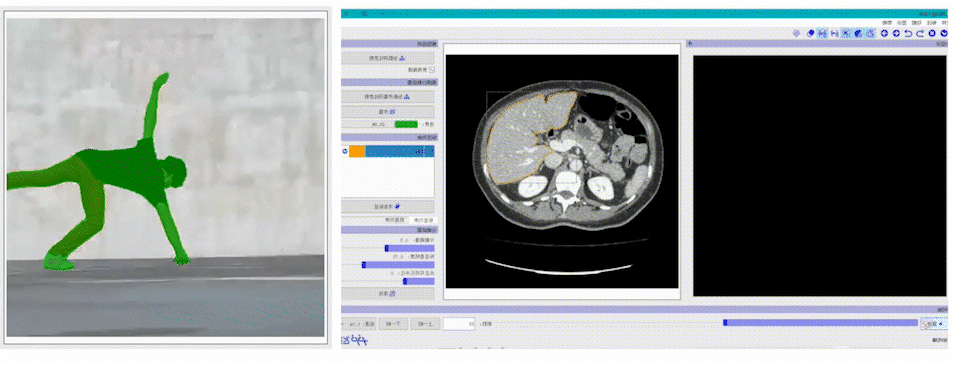
支持多种图像及标注格式EISeg正式版支持多种标注格式生成,同时支持导出伪彩色图、灰度图,以及JSON、COCO等数据格式,总有一款能满足你的需求。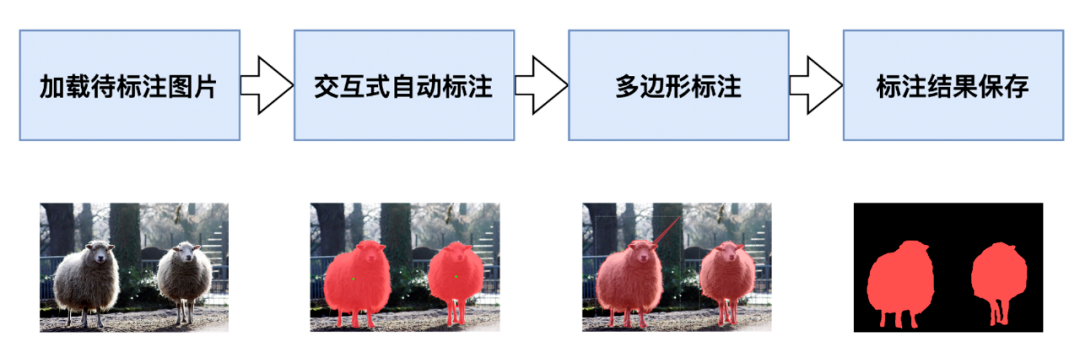
助力多家标注平台落地PaddleSeg提供的智能标注能力现已落地百度大脑EasyData智能数据服务平台,百度智能云数据众包、标贝数据、中国空天院、国家农业智能装备工程技术研究中心等厂内外数十家公司,助力企业提升标注效率,降低标注成本。
EISeg传送门https://github.com/PaddlePaddle/PaddleSeg/tree/release/2.6/EISeg
4.2 PP-HumanSegV2人像分割SOTA方案,精度96.63%、速度63FPS
在视频通话和观看直播时,背景虚化、弹幕穿人等神奇的功能,给我们带来了更优质的体验和多维的乐趣。那这是靠什么AI黑科技实现的呢?答案就是人像分割。人像分割是将人物和背景在像素级别进行区分。目前人像分割技术得到快速突破,但是高精度、高性能、全流程的方案,仍是业界高手持续发力优化的地方。
PaddleSeg重磅升级的PP-HumanSegV2人像分割方案,以96.63%的mIoU精度, 63FPS的手机端推理速度,再次刷新开源人像分割算法SOTA指标。相比PP-HumanSegV1方案,推理速度提升87.15%,分割精度提升3.03%,可视化效果更佳。支持零成本、开箱即用!
PP-HumanSegV2方案核心点在以下三方面:
开源PP-HumanSeg14K人像分割数据集常见的人像分割公开数据集有EG1800和Supervise-Portrait,数据量分别是1.8k和3k,而且都是针对通用场景。PP-HumanSegV2方案重点关注视频会议和远程通话场景,面临场景变化多样、可用数据量过少的难点。因此,我们针对视频会议和远程通话场景,构建并开源了最大的视频会议人像分割数据集PP-HumanSeg14K。该数据集充分考虑了场景多样性,采集的图片涵盖了背景光照、人物动作、人物个数、戴口罩等诸多变化因素。总共收集了将近14000张图片进行高精标注,划分为训练集9000张、验证集2500张、测试集2500张。
同时PaddleSeg团队将PP-HumanSeg14K数据集论文发表在WACV 2022 Workshop上,让更多学者可以看到并申请使用该数据集。截至目前,PP-HumanSeg14K已经广泛助力人像分割的研究,涵盖60+高校、20+机构、30+公司。
PP-HumanSeg14K数据集传送门https://github.com/PaddlePaddle/PaddleSeg/blob/release/2.6/contrib/PP-HumanSeg/paper.md 采集的图片
采集的图片 标注的图片
标注的图片
升级实时高精度人像分割SOTA模型
此前的实时人像分割模型,无法实现精度和速度的完美平衡,所以我们基于PaddleSeg近期发布的超轻量级系列MobileSeg模型,根据方案目标,设计新的实时人像分割SOTA模型模型。(结构如下图所示)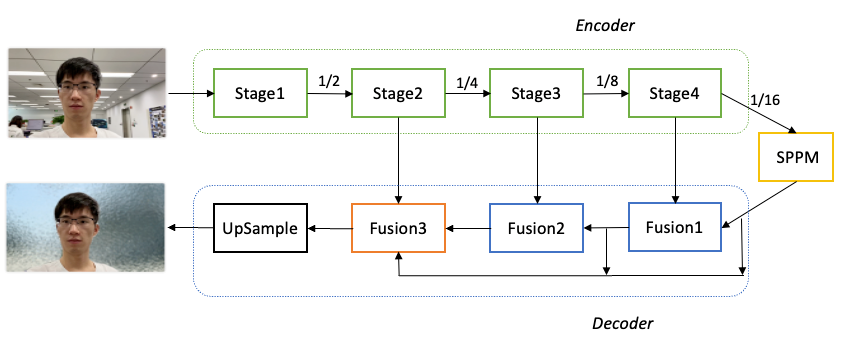 实时人像分割SOTA模型对于模型Encoder部分,考虑到模型的算量要求很高,我们选用MobileNetV3作为骨干网络提取多层特征。分析发现MobileNetV3的参数主要集中在最后一个Stage,在不影响分割精度的前提下,我们只保留MobileNetV3的前四个Stage,成功减少了68.6%的参数量。对于上下文部分,我们使用PP-LiteSeg模型中提出的轻量级SPPM模块,而且其中的普通卷积都替换为可分离卷积,进一步减小计算量。SPPM模块输入16倍下采样特征图,输出汇集全局上下文信息的特征图。对于Decoder部分,我们设计三个Fusion融合模块,多次融合深层语义特征和浅层细节特征,最后一个Fusion融合模块再次汇集不同层次的特征图,输出分割结果。
实时人像分割SOTA模型对于模型Encoder部分,考虑到模型的算量要求很高,我们选用MobileNetV3作为骨干网络提取多层特征。分析发现MobileNetV3的参数主要集中在最后一个Stage,在不影响分割精度的前提下,我们只保留MobileNetV3的前四个Stage,成功减少了68.6%的参数量。对于上下文部分,我们使用PP-LiteSeg模型中提出的轻量级SPPM模块,而且其中的普通卷积都替换为可分离卷积,进一步减小计算量。SPPM模块输入16倍下采样特征图,输出汇集全局上下文信息的特征图。对于Decoder部分,我们设计三个Fusion融合模块,多次融合深层语义特征和浅层细节特征,最后一个Fusion融合模块再次汇集不同层次的特征图,输出分割结果。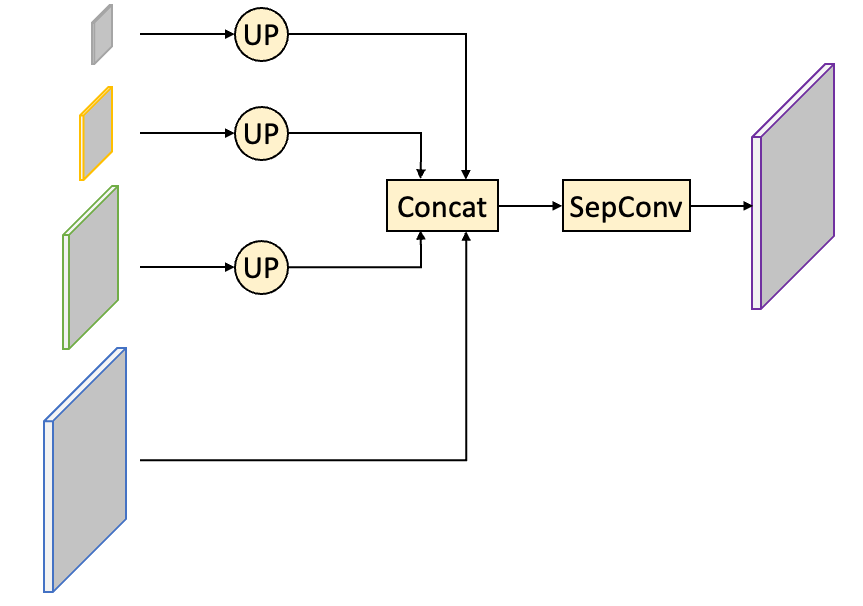 多层次特征融合模块
多层次特征融合模块
三个关键优化策略升级除了数据和模型方面的工作,我们还分析实际场景,提出了三种优化策略,实现最好的精度、速度和可视化效果:(1)使用两阶段训练方式,提升分割精度:两阶段训练是基于迁移学习的思想,首先在大规模混合人像数据集(数据量100k+)上训练,然后使用该预训练权重,在PP-HumanSeg14K数据集(数据量14k)上训练,最终得到训练好的模型。使用两阶段训练方式,可以充分利用其他数据集,提高模型的分割精度和泛化能力。(2)调整图像分辨率,提升推理速度:调整图像分辨率也直接影响模型的推理速度,我们使用多种图像分辨率进行训练和测试,在PP-HumanSegV2方案中选择最佳图像分辨率,进一步提升了模型推理速度。(3)使用形态学后处理,提升可视化效果:首先获取原始预测图像I,然后使用阈值处理、图像腐蚀、图像膨胀等操作得到掩码图像M,最后预测图像I和掩码图像M相乘,输出最终预测图像O。下图直观展示了形态学后处理可以滤除背景干扰,提升可视化效果。
 形态学后处理的图像传送门https://github.com/PaddlePaddle/PaddleSeg/tree/release/2.6/contrib/PP-HumanSeg
形态学后处理的图像传送门https://github.com/PaddlePaddle/PaddleSeg/tree/release/2.6/contrib/PP-HumanSeg
PaddleSeg技术分享直播课
官网地址https://www.paddlepaddle.org.cnPaddleSeg
项目地址(GitHub)https://github.com/PaddlePaddle/PaddleSegGitee
https://gitee.com/paddlepaddle/Paddleseg